A Tool for Training AI
How can we help our customers see value sooner?
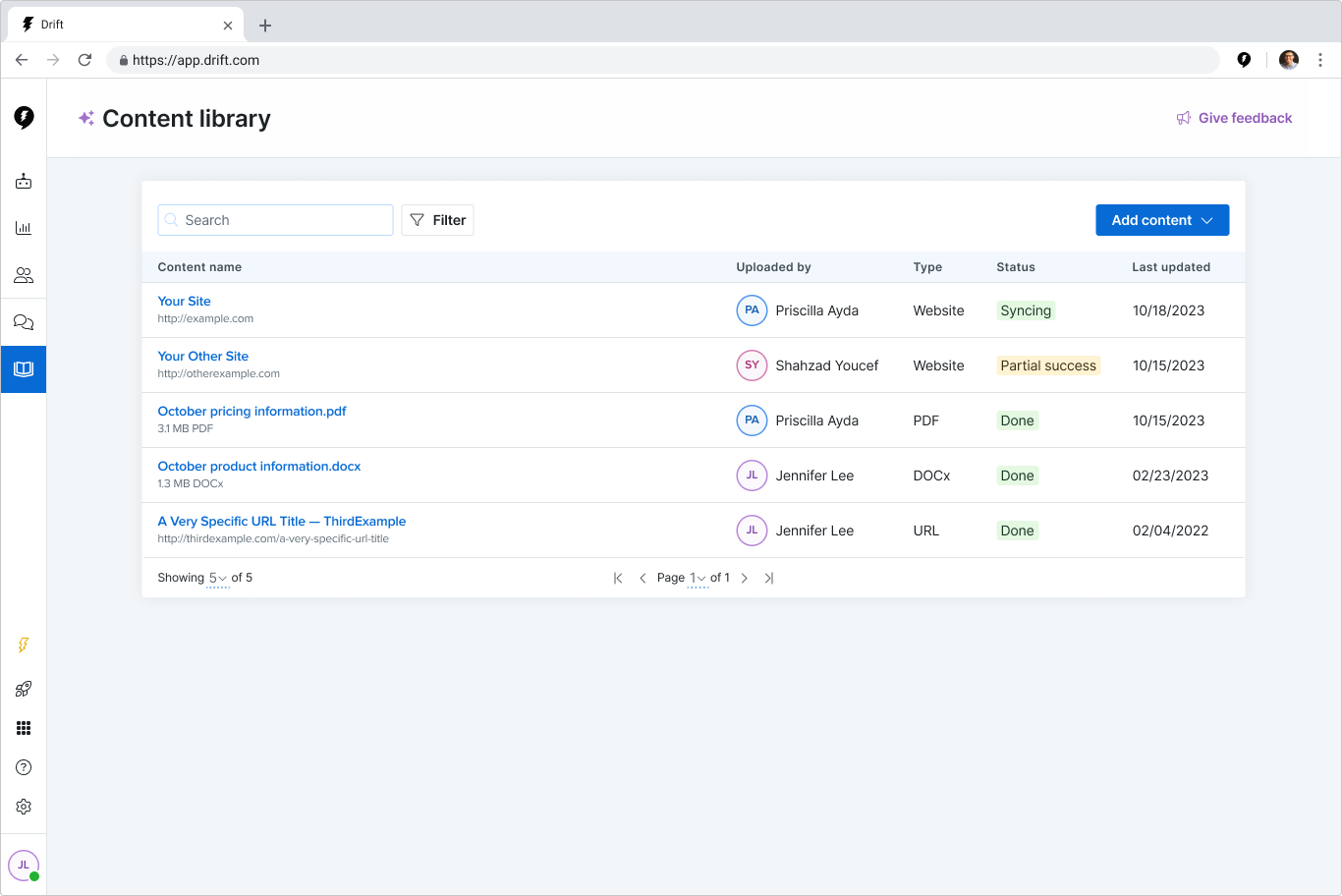
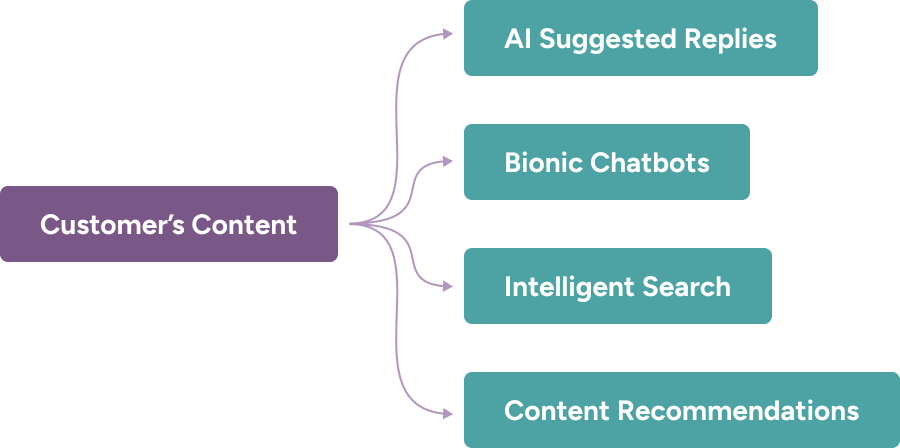
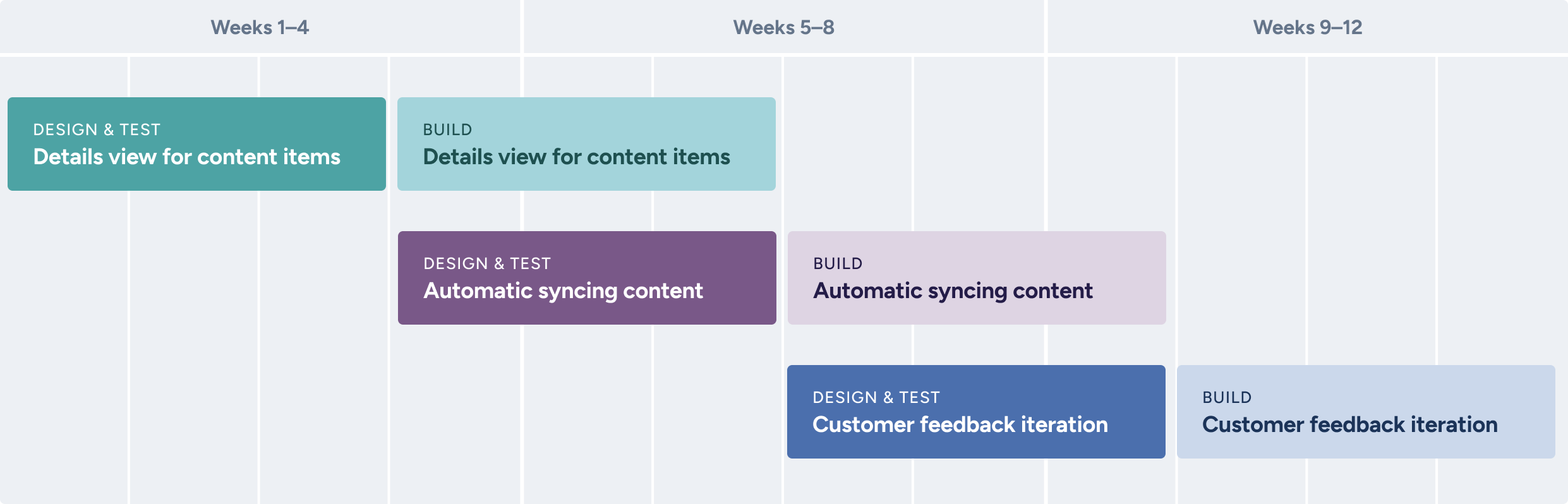
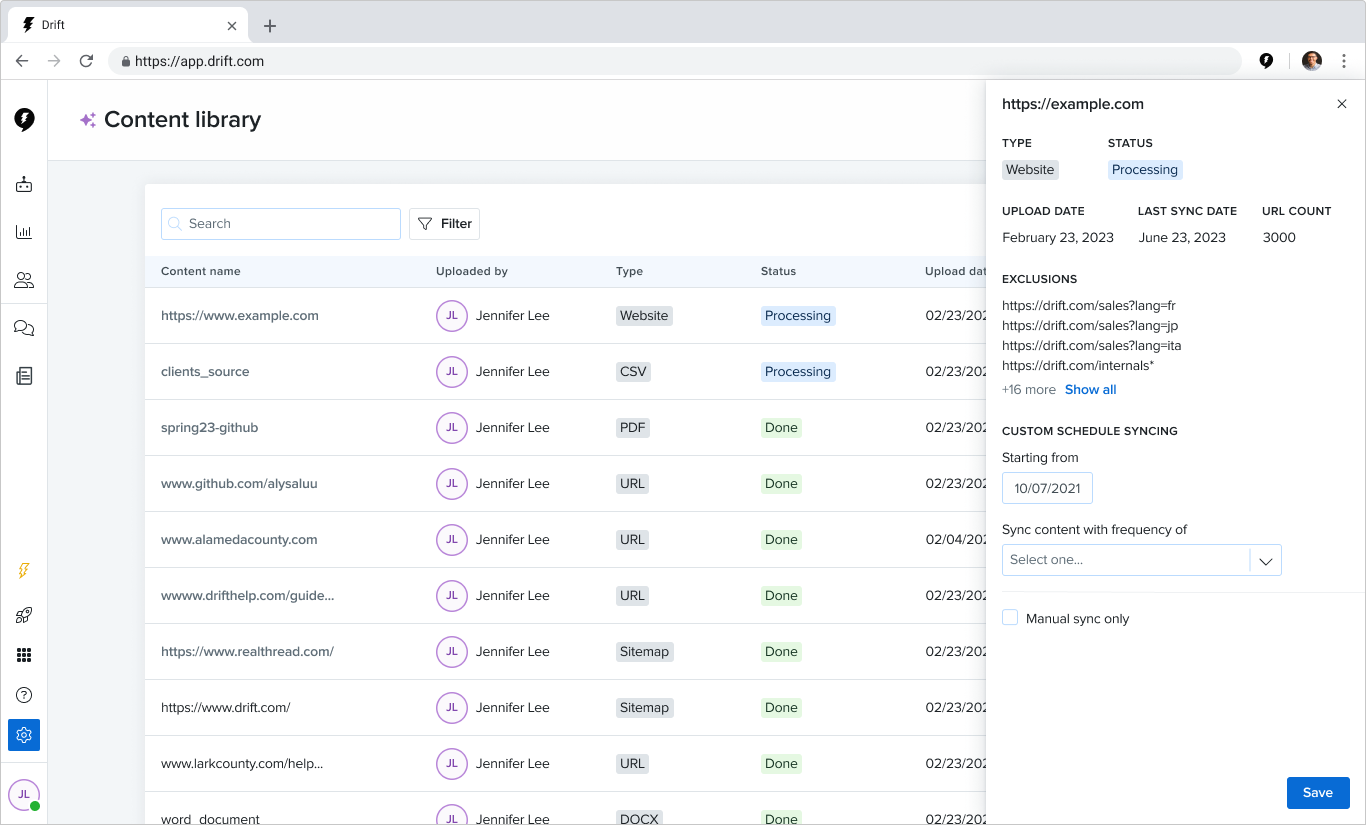
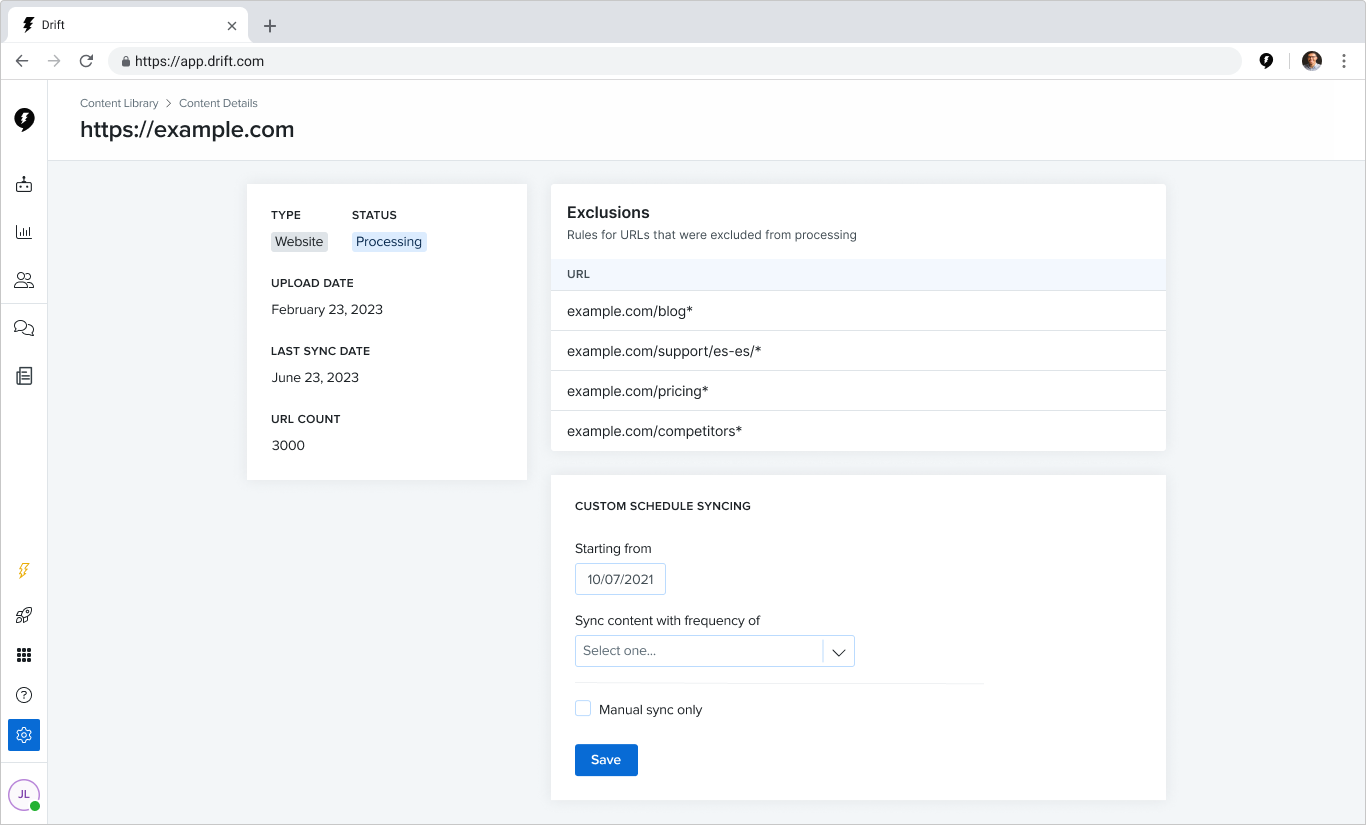
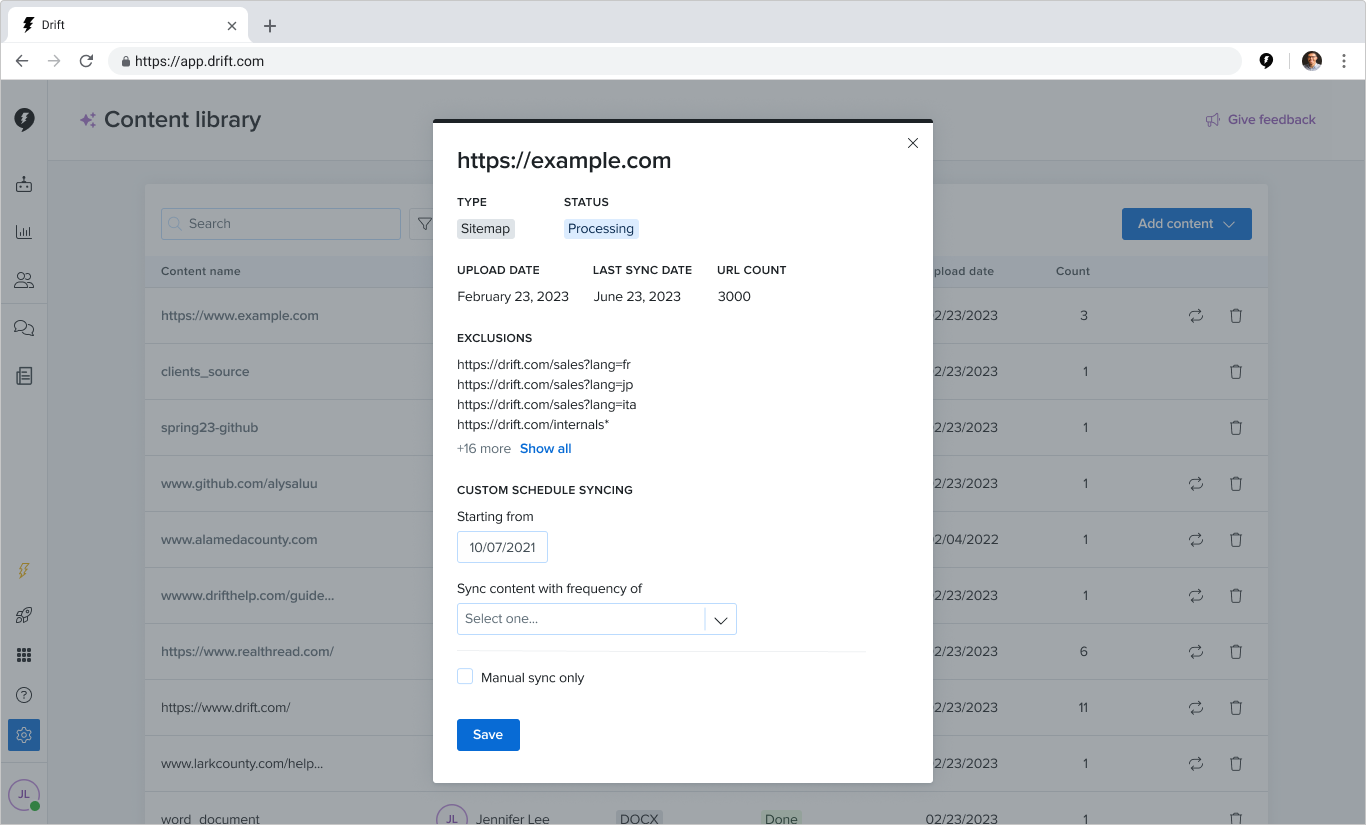
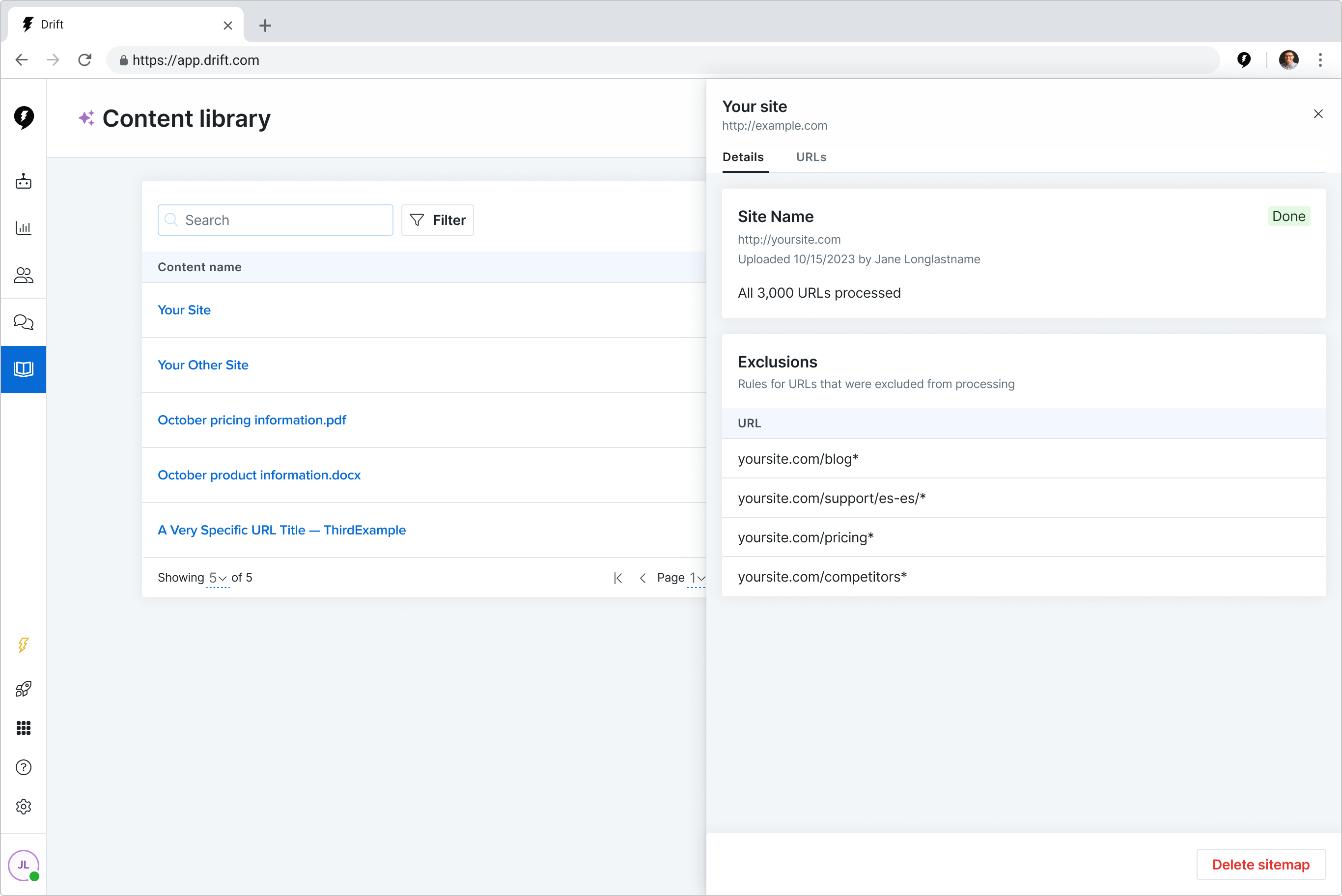
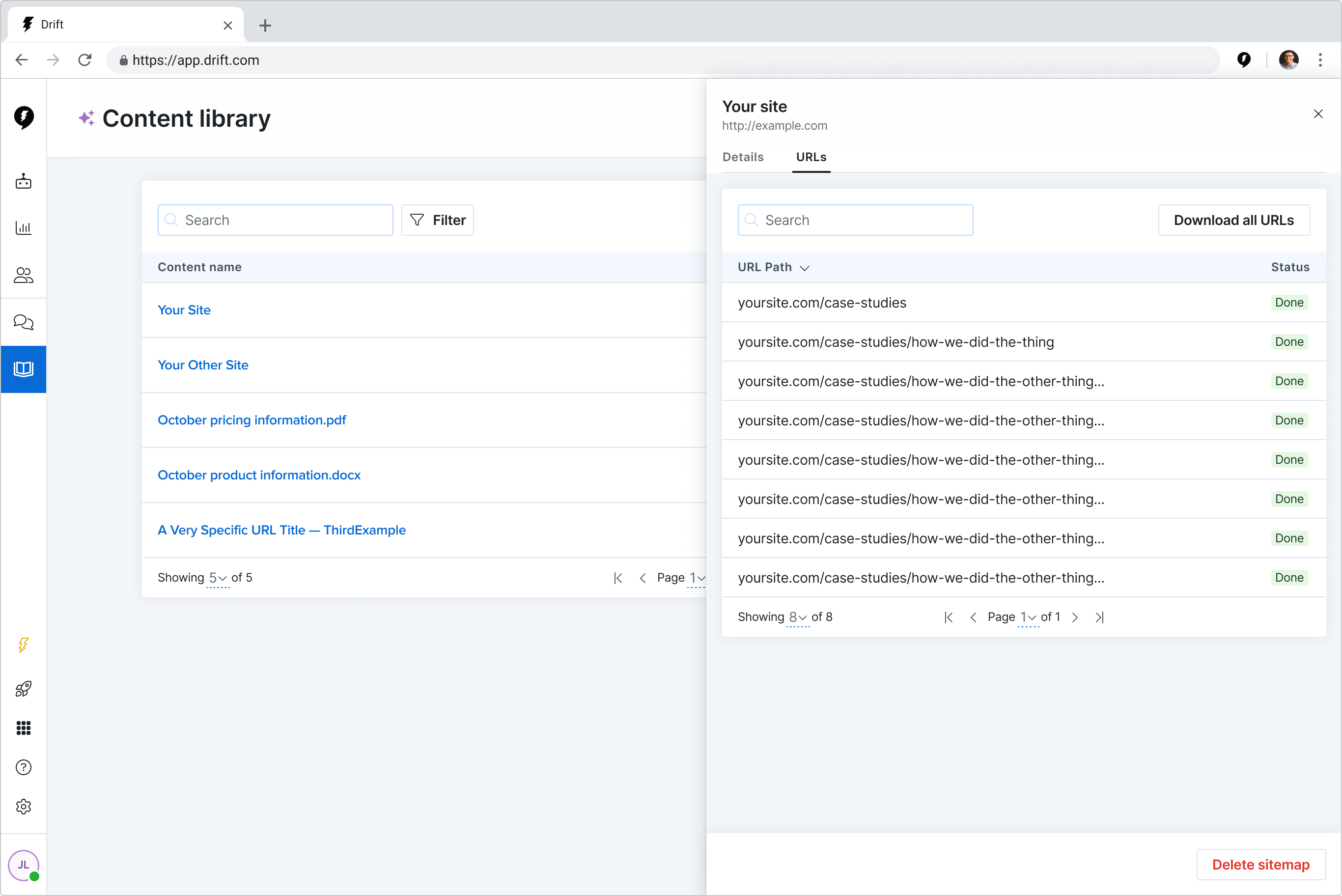
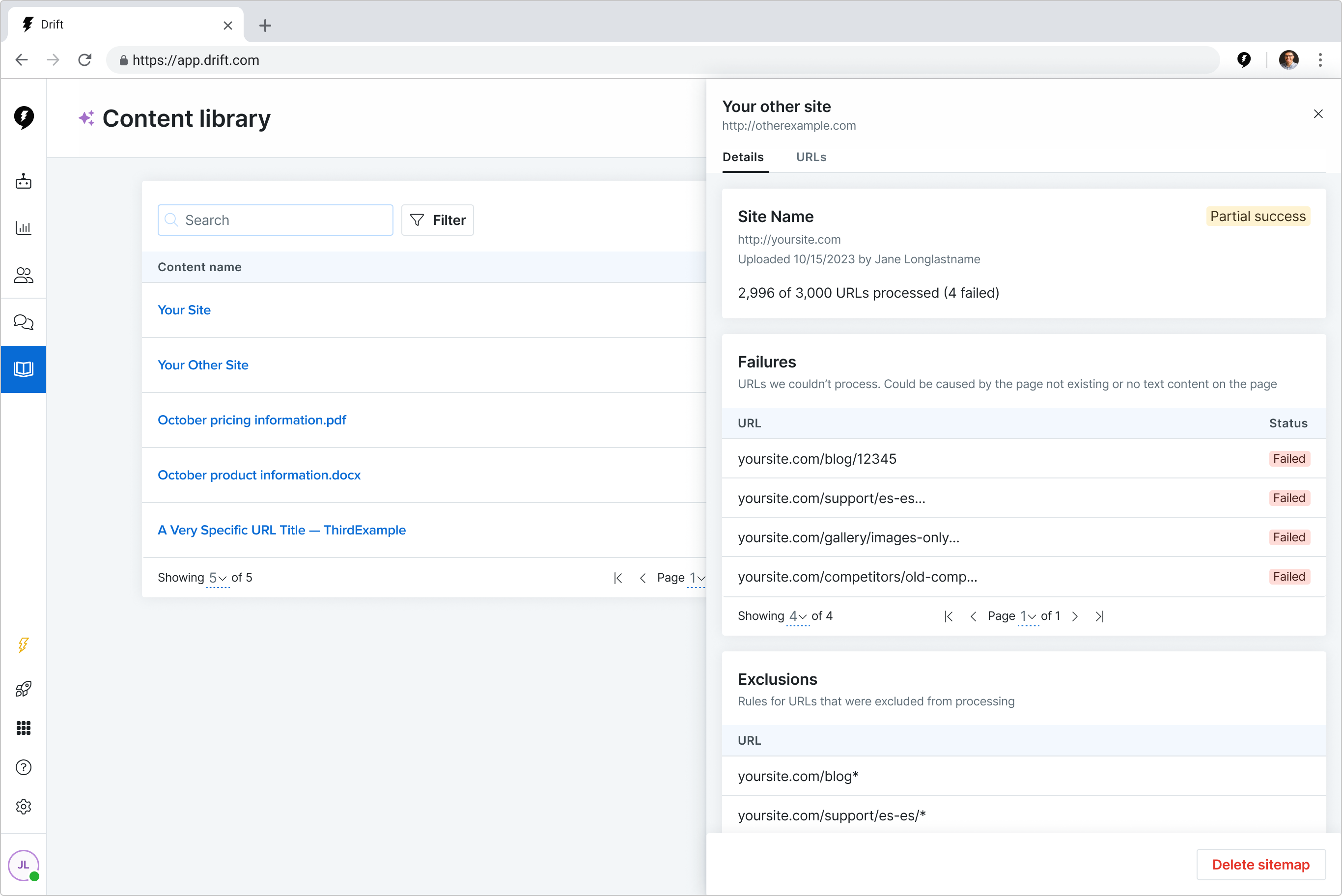
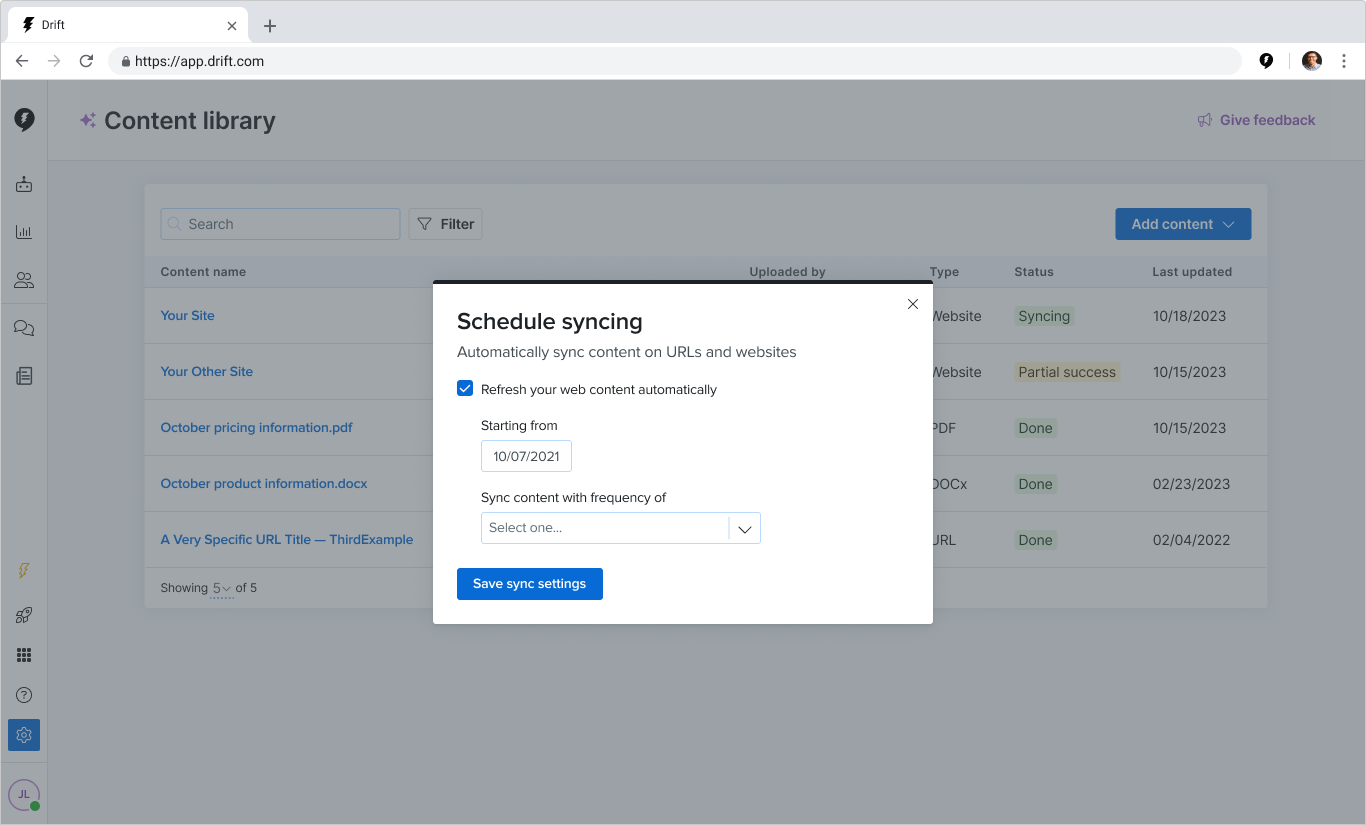
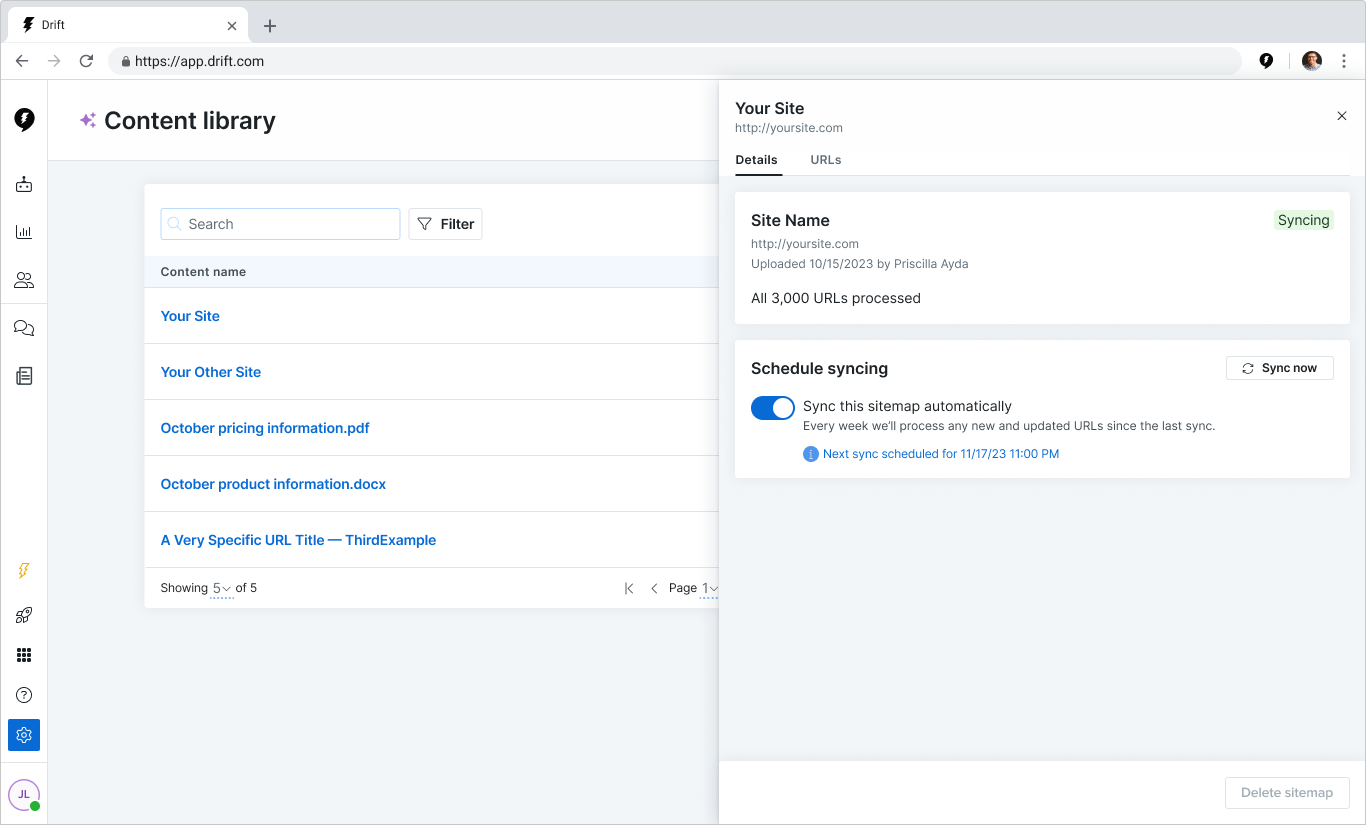
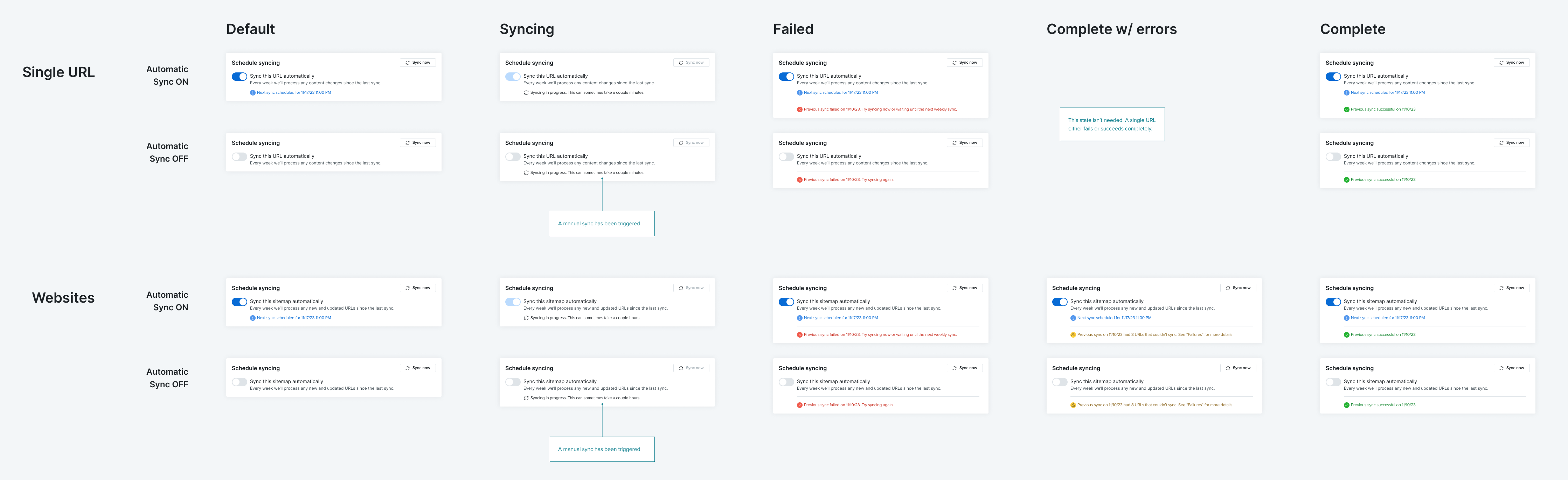
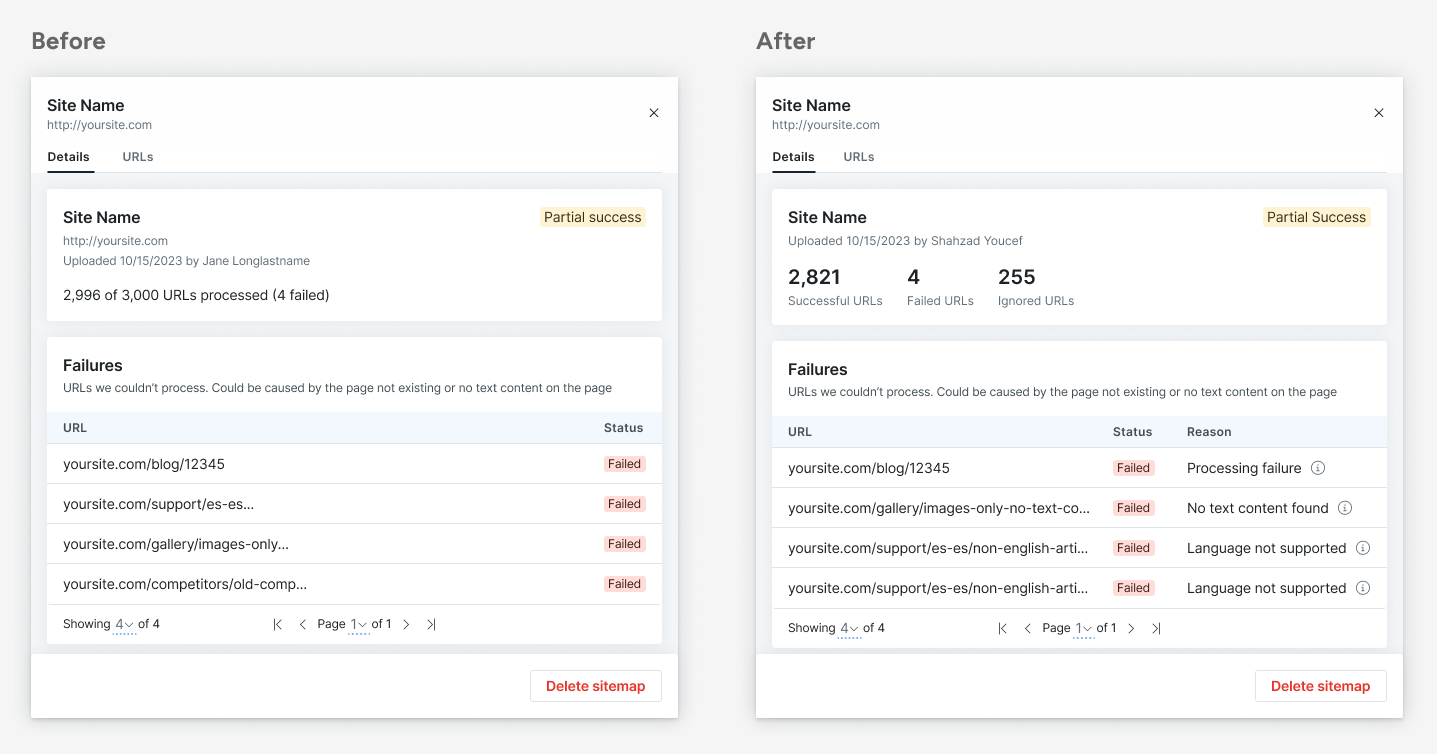
In 12 weeks, my team turned a proof-of-concept tool into a launch-ready feature that helped customers upload content to train and use Drift’s new AI-powered tools.
Our work resulted in a reduction in the time it took a customer to see value from 6 days to 3.5 hours.